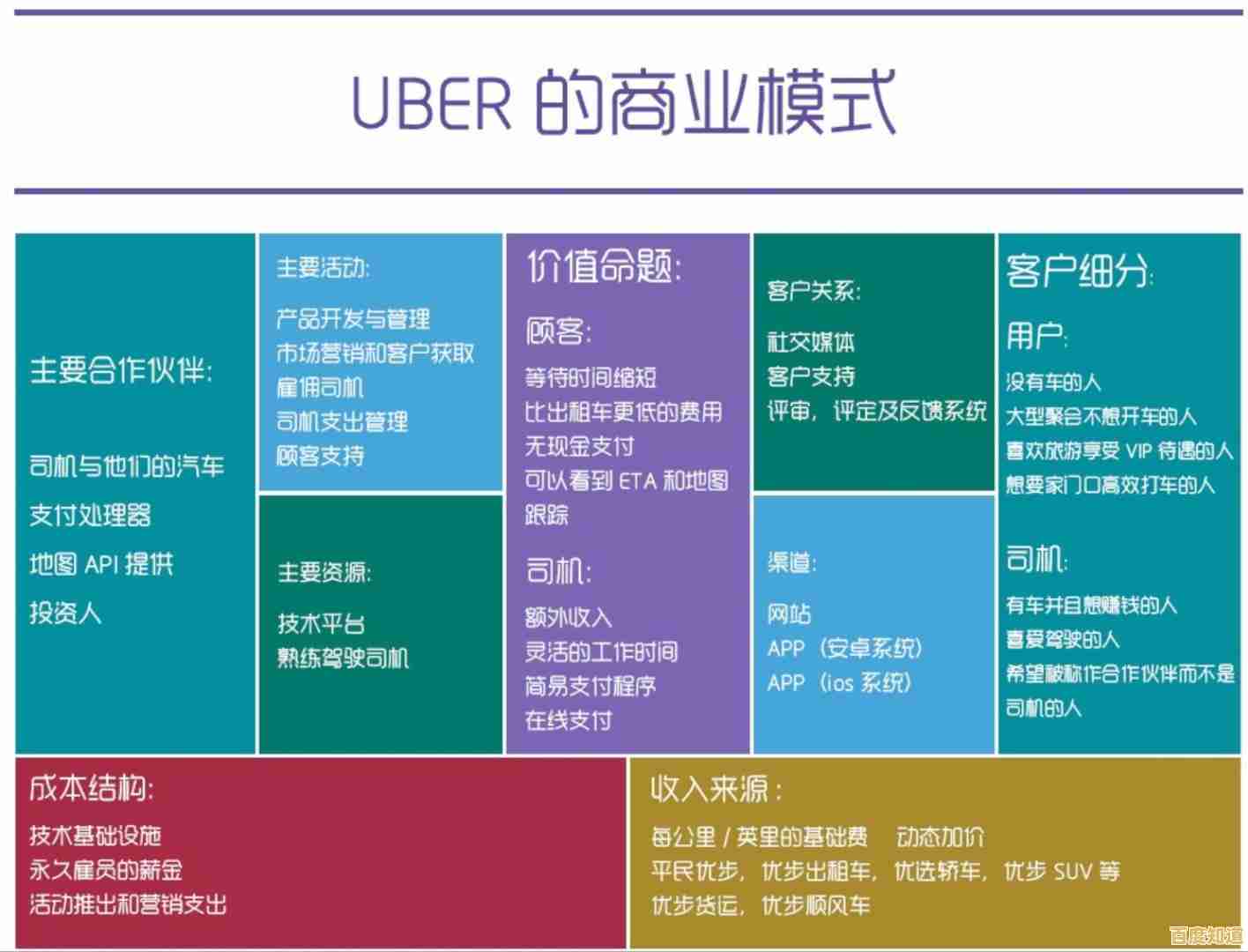
GPU服务器性能天梯榜:强劲算力赋能高效计算新纪元!

在当今这个数据爆炸的时代,人工智能、科学模拟、高清视频渲染等尖端技术正以前所未有的速度发展,而驱动这些技术前进的核心引擎,正是拥有强大计算能力的GPU服务器,它们就像是数字世界的超级大脑,处理着海量信息,将复杂的计算任务从几天甚至几周缩短到几小时或几分钟,为了让大家更清晰地了解目前市场上这些“算力巨兽”的性能高低,我们特别整理了这份GPU服务器性能天梯榜,希望能为需要强大计算能力的个人开发者、科研机构和企业提供一个直观的参考,需要说明的是,性能排名并非绝对,会根据具体任务类型和优化程度有所变化,但本榜单旨在给出一个综合性能的宏观视角。
位于天梯榜顶端、代表当前最强算力巅峰的,无疑是搭载了NVIDIA H100 Tensor Core GPU的服务器系统,根据NVIDIA官方发布的技术规格和各大云服务商(如AWS、Azure、Google Cloud)提供的实例性能数据,H100是专为大规模人工智能和高性能计算设计的,它采用了革命性的Hopper架构,特别是在处理像ChatGPT这类超大型语言模型的训练时,其速度比前代产品A100有数倍的提升,如果你需要进行最前沿的AI研究、超大规模的深度学习模型训练,或者极其复杂的科学计算,那么基于H100构建的服务器集群就是目前你能找到的最强工具。
紧随其后,同样处于顶尖行列的是NVIDIA的A100 GPU服务器,虽然H100已经发布,但A100作为上一代的旗舰产品,其性能和生态系统依然非常强大,在市场上拥有广泛的应用基础,根据众多科技媒体和评测机构的测试报告,A100在大多数AI训练和推理任务、数据分析以及高性能计算中,依然能够提供极其卓越的性能,对于许多企业级应用和科研项目来说,基于A100的服务器在性能和成本之间取得了很好的平衡,是目前数据中心里名副其实的“主力军”。
再往下,我们来到了高性能计算和高端图形工作站领域的重要角色——NVIDIA V100和A6000/8000系列,V100虽然已经是较早的架构,但其强大的双精度浮点计算能力使其在传统科学计算和某些特定领域的模拟中依然占有一席之地,而RTX A6000和A8000则更像是图形和计算的结合体,根据专业硬件评测网站如AnandTech的分析,它们不仅拥有强大的渲染能力,也具备可观的AI计算性能,非常适合需要同时进行高质量可视化交互和复杂计算的场景,比如高级别的产品设计、建筑信息模型以及医学成像分析等。
在中高端市场,NVIDIA的RTX 4090是一个不可忽视的特殊存在,虽然它主要面向消费级游戏市场,但根据众多开发者社区和博主的实际测试,其单卡在AI推理和一些模型的训练任务中,展现出了惊人的性价比,它的浮点运算能力甚至超越了一些旧款的专业卡,许多预算有限的研究小组或个人开发者,会选择使用多张RTX 4090来搭建自己的小型AI计算平台,用于模型实验和中等规模的任务处理。
这个舞台上并非只有NVIDIA一位玩家,AMD的MI系列加速器,特别是MI250X和最新发布的MI300X,正以其强大的性能向领先者发起挑战,根据AMD官方公布的基准测试结果以及与合作伙伴的案例展示,MI250X在部分HPC应用中表现优异,而MI300X则集成了CPU和GPU,旨在为生成式AI工作负载提供更高的能效和内存带宽,虽然目前软件生态和普及度尚不及NVIDIA,但AMD的进步为市场提供了重要的选择,促进了良性的竞争。
我们不能忘记那些为特定任务而生的定制化解决方案,例如谷歌自主研发的TPU,根据谷歌云平台的技术文档和学术论文介绍,TPU是专门为TensorFlow等机器学习框架优化的张量处理器,在运行谷歌自家的搜索、翻译等服务以及提供给用户进行AI训练时,表现出极高的效率和速度,它在特定的AI应用场景下,其性能甚至可以媲美顶级的GPU。
GPU服务器的性能天梯榜是一个动态变化的图景,它反映了计算技术日新月异的发展,从称霸的H100到经典的A100,从高性价比的消费级显卡到异军突起的竞争对手和定制化芯片,每一种选择都对应着不同的需求和预算,理解这份榜单,有助于我们在迈向高效计算新纪元的道路上,更精准地找到那把开启未来的“算力钥匙”。

本文由韦斌于2025-11-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://jing.xlisi.cn/wenda/71544.html